
[방법1] notebook 시작 부분에 아래 magic command를 입력한다. %config IPCompleter.use_jedi = False [방법2] User home directory에 ipython config 파일을 입력한다. (Example : C:\Users\user01\.ipython\profile_default\ipython_config.py) c.IPCompleter.use_jedi = False [방법3] jedi package를 삭제한다. pip uninstall jedi [참고] https://stackoverflow.com/questions/40536560/ipython-and-jupyter-autocomplete-not-working http://www.legendu.ne..
 Anaconda에서 python 가상 환경 사용하기
Anaconda에서 python 가상 환경 사용하기
Anaconda Prompt를 실행한 후 현재 가상환경을 확인한다. conda env list python version을 확인한다. python --version 가상 환경을 생성한다. conda create --name test_venv python=3.8 생성한 가상 환경을 확인한다. conda env list 가상 환경을 활성화한다. conda activate test jupyterlab을 설치한다. conda install jupyterlab jupyterlab을 실행한다. jupyter lab 가상 환경 삭제하기 conda deactivate conda remove --name test_venv --all [참고] https://niceman.tistory.com/85

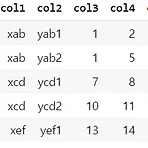 pandas groupby 함수 사용하기
pandas groupby 함수 사용하기
[준비] dataframe 생성 import pandas as pd list_val = [ ['xab', 'yab1', 1, 2, 3], ['xab', 'yab2', 1, 5, 6], ['xcd', 'ycd1', 7, 8, 9], ['xcd', 'ycd2', 10, 11, 12], ['xef', 'yef1', 13, 14, 15] ] list_col = ['col1', 'col2', 'col3', 'col4', 'col5'] list_idx = ['a', 'b', 'c', 'd', 'e'] df_a = pd.DataFrame(list_val, columns=list_col, index=list_idx) df_a 1개 column 기준으로 grouping하여 모든 data를 조회한다. df_a.groupb..
 numpy 숫자 배열 생성하기
numpy 숫자 배열 생성하기
ones, zeros, full, arange, random.randint 함수를 사용할 수 있다. [준비] import import numpy as np ones 함수를 사용해 1을 입력한다. narr_a = np.ones((2, 5)) narr_a zeros 함수를 사용해 0을 입력한다. narr_b = np.zeros((2, 5)) narr_b full 함수를 사용해 특정 숫자를 입력한다. narr_c = np.full((2, 5), 7) narr_c arange 함수를 사용해 범위 내 순서가 있는 숫자를 입력한다. narr_d = np.arange(1, 11, 1).reshape(2, 5) narr_d random.randint 함수를 사용해 범위 내 순서가 없는 숫자를 입력한다. narr_e =..
 pandas dataframe 조건 조회하기
pandas dataframe 조건 조회하기
[준비] dataframe 생성 import pandas as pd list_val = [ ['xab1', 'yab1', 1, 2, 3], ['xab2', 'yab2', 1, 5, 6], ['xcd3', 'ycd3', 7, 8, 9], ['xcd4', 'ycd4', 10, 11, 12], ['xef5', 'yef5', 13, 14, 15] ] list_col = ['col1', 'col2', 'col3', 'col4', 'col5'] list_idx = ['a', 'b', 'c', 'd', 'e'] df_a = pd.DataFrame(list_val, columns=list_col, index=list_idx) df_a 1개 숫자 column을 비교하여 조회한다. df_a.loc[df_a['col3'] ..
 pandas dataframe에서 integer location으로 dataframe 조회하기
pandas dataframe에서 integer location으로 dataframe 조회하기
[준비] dataframe 생성 import pandas as pd list_val = [ [1, 2, 3], [1, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15] ] list_col = ['col1', 'col2', 'col3'] list_idx = ['a', 'b', 'c', 'd', 'e'] df_a = pd.DataFrame(list_val, columns=list_col, index=list_idx) df_a ※ integer location은 조회한 dataframe에서 보이지 않는다. [방법1] row integer loaction 기준으로 dataframe 1개 조회 df_a.iloc[[0]] ※ [0] 대신 0을 입력하면 dataframe이 아니라 ser..
 pandas dataframe에서 column으로 dataframe 조회하기
pandas dataframe에서 column으로 dataframe 조회하기
[준비] dataframe 생성 import pandas as pd list_val = [ ['x1', 'y1', 1, 2, 3], ['x2', 'y2', 1, 5, 6], ['x3', 'y3', 7, 8, 9] ] list_col = ['col1', 'col2', 'col3', 'col4', 'col5'] list_idx = ['a', 'b', 'c'] df_a = pd.DataFrame(list_val, columns=list_col, index=list_idx) df_a 1개의 column의 구성된 dataframe을 조회한다. loc를 사용하는 대신 대괄호 2개를 사용한다. df_a[['col1']] ※ df_a.loc[:, ['col1']] 표현으로도 동일한 결과를 조회할 수 있다. (row 생..
- Total
- Today
- Yesterday