Programming
pandas groupby 함수 사용하기
engyjoon
2021. 1. 25. 15:37
[준비] dataframe 생성
import pandas as pd
list_val = [
['xab', 'yab1', 1, 2, 3],
['xab', 'yab2', 1, 5, 6],
['xcd', 'ycd1', 7, 8, 9],
['xcd', 'ycd2', 10, 11, 12],
['xef', 'yef1', 13, 14, 15]
]
list_col = ['col1', 'col2', 'col3', 'col4', 'col5']
list_idx = ['a', 'b', 'c', 'd', 'e']
df_a = pd.DataFrame(list_val, columns=list_col, index=list_idx)
df_a
1개 column 기준으로 grouping하여 모든 data를 조회한다.
df_a.groupby(['col1']).sum()
※ ['col1'] 대신 'col1'을 사용하면 series로 조회된다.
※ as_index=False 옵션을 사용하면 index가 column으로 조회된다.
2개 column 기준으로 grouping하여 모든 data를 조회한다.
df_a.groupby(['col1', 'col2']).sum()
1개 column 기준으로 grouping하여 일부 data를 조회한다.
df_a.groupby(['col1'])[['col3']].sum()
1개 column 기준으로 grouping하고 여러 개 통계 함수를 사용해 일부 data를 조회한다.
df_a.groupby(['col1'])['col3'].agg(['count', 'sum'])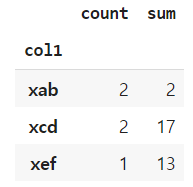
[참고]